주소창에 도메인을 치면 벌어지는 일
사람은 example.com 같은 이름을 기억하지만, 컴퓨터는 숫자로 된 IP 주소로만 서로를 찾습니다. 이 둘 사이를 이어주는 번역 체계가 DNS(Domain Name System)입니다. 브라우저 주소창에 도메인을 입력하는 순간, 화면에 페이지가 뜨기 전에 이미 여러 대의 서버가 도메인을 IP로 바꾸는 조회를 마칩니다. 이 과정은 보통 수십 밀리초 안에 끝나기 때문에 사용자는 그 존재를 거의 느끼지 못합니다.
DNS가 없다면 우리는 웹사이트마다 숫자 주소를 외워야 할 것입니다. 전화번호부 없이 모든 사람의 번호를 기억해야 하는 것과 같습니다. DNS는 그 방대한 전화번호부를 전 세계에 분산해두고, 누구든 이름만 알면 번호를 찾을 수 있게 해주는 인터넷의 기반 시설입니다. 그래서 DNS가 흔들리면 정작 서버는 멀쩡해도 사용자가 도달하지 못하는 사태가 벌어집니다.
DNS 조회에 참여하는 네 종류의 서버
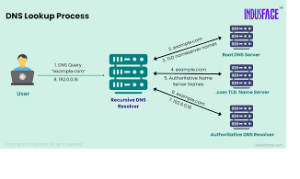
도메인 하나를 IP로 바꾸는 데에는 역할이 다른 서버 네 종류가 단계적으로 관여합니다. 각자 아는 범위가 정해져 있어, 모르는 부분은 다음 서버에게 넘기는 방식으로 답을 좁혀갑니다.
리커시브 리졸버
조회의 출발점이자 심부름꾼입니다. 보통 통신사(ISP)나 1.1.1.1 같은 공용 리졸버가 이 역할을 맡습니다. 클라이언트의 요청을 받아 나머지 서버들에게 대신 물어보고, 답을 모아 돌려줍니다. 자주 찾는 도메인은 캐시에 저장해 두었다가 곧바로 답하기 때문에, 매번 전체 과정을 반복하지는 않습니다. 사실상 대부분의 조회는 이 단계의 캐시에서 해결됩니다.
루트 네임서버
리졸버의 캐시에 답이 없을 때 가장 먼저 묻는 곳입니다. 루트 서버는 최종 IP를 직접 알지는 못하지만, .com이나 .net 같은 최상위 도메인(TLD)을 누가 담당하는지 알려줍니다. 전 세계에 분산 배치돼 있어 일부가 멈춰도 조회가 이어집니다.
TLD 네임서버
.com을 담당하는 TLD 서버는 example.com의 권한 있는 네임서버가 어디인지 가리킵니다. 도메인 이름을 뒤에서부터 거슬러 올라가며 범위를 좁혀가는 방식입니다. 루트가 “닷컴은 저쪽”이라 말하면, 닷컴 서버가 “그 도메인은 이 서버가 안다”고 한 단계 더 좁혀주는 셈입니다.
권한 있는 네임서버
조회의 종착점입니다. 해당 도메인의 실제 IP 주소를 담은 레코드를 가지고 있어, 리졸버에게 최종 답을 건넵니다. 이 답이 클라이언트로 돌아가면 브라우저가 비로소 그 IP로 서버에 접속합니다. 도메인 소유자가 IP를 바꾸면 이 서버의 레코드를 수정하게 됩니다. 각 서버의 세부 역할은 Cloudflare Learning의 DNS 서버 유형 문서에 자세히 정리돼 있습니다.
레코드의 종류
DNS는 단순히 이름을 IP로 바꾸는 일만 하지 않습니다. 용도에 따라 여러 종류의 레코드를 둡니다. 이름을 IPv4 주소로 잇는 A 레코드, IPv6 주소로 잇는 AAAA 레코드, 한 이름을 다른 이름으로 넘기는 CNAME, 메일 서버를 가리키는 MX 레코드 등이 대표적입니다. 하나의 도메인이 여러 레코드를 동시에 가질 수 있어, 웹은 이쪽으로 메일은 저쪽으로 나눠 보내는 식의 구성이 가능합니다. 이 레코드들을 어떻게 짜느냐에 따라 같은 도메인도 전혀 다르게 동작합니다.
캐싱이 속도를 좌우한다
만약 모든 요청이 매번 루트부터 권한 서버까지 거친다면 웹은 지금보다 훨씬 느릴 것입니다. 그래서 리졸버, 운영체제, 브라우저는 각 단계에서 조회 결과를 일정 시간 동안 보관합니다. 이 보관 기간을 TTL(Time To Live)이라 부르며, 레코드마다 다르게 설정됩니다.
TTL을 길게 잡으면 캐시가 오래 유지돼 조회 부담이 줄지만, IP를 바꿨을 때 변경이 퍼지는 데 시간이 걸립니다. 짧게 잡으면 변경이 빠르게 반영되는 대신 조회가 잦아져 부하가 늘어납니다. 그래서 서버 이전을 앞두고는 미리 TTL을 줄여두었다가, 이전이 끝나면 다시 늘리는 식의 운영 기법을 씁니다. DNS 위에서 트래픽이 한곳에 쏠리지 않게 분산하는 것은 트래픽 분산 설계의 연장선이며, 응답을 여러 지역에서 동시에 내보내는 구조는 애니캐스트 기반 CDN과 맞물립니다.
재귀 조회와 반복 조회
조회 방식에는 두 가지가 있습니다. 클라이언트가 리졸버에게 “답을 끝까지 구해서 달라”고 통째로 맡기는 것이 재귀 조회입니다. 사용자 입장에서는 한 번 묻고 완성된 답을 받으니 편리합니다. 반면 리졸버가 루트, TLD, 권한 서버를 차례로 직접 찾아다니며 한 단계씩 좁혀가는 것이 반복 조회입니다.
실제로는 이 둘이 결합해 동작합니다. 클라이언트는 리졸버에게 재귀로 맡기고, 그 요청을 받은 리졸버는 여러 서버를 반복 조회로 돌며 답을 모읍니다. 즉 사용자가 느끼는 편리함 뒤에서 리졸버가 복잡한 심부름을 대신 해주는 구조입니다. 이렇게 역할을 나눈 덕분에 클라이언트는 가볍게 유지되고, 캐싱이나 보안 같은 무거운 기능은 리졸버에 모아 관리할 수 있습니다.
보안 측면의 약점과 보완
DNS는 설계 당시 신뢰를 전제로 만들어져, 들어온 응답을 의심 없이 받아들입니다. 이 점을 노려 위조된 응답을 끼워 넣어 사용자를 가짜 사이트로 보내는 공격이 가능했습니다. 이를 막기 위해 응답에 전자 서명을 붙여 변조 여부를 검증하는 DNSSEC가 도입됐습니다. 또한 조회 내용 자체가 평문보안적으로 노출되는 부분을조회해 암호화하는 DoH와 DoT도 널리 쓰입니다. DNS의 기본 동작 원리는 IETF RFC 1034(도메인 네임 개념 표준 문서)에 그 원형이 정의돼 있습니다.